A look into VssVer2.scc and VssVer.scc file format
Why VssVer.scc?
I've seen a couple of times asked questions related to the format of the Vssver.scc or Vssver2.scc files.
Knowing the file format would allow interesting 3rd party tools to be written, here are just a couple of ideas:
- "ss have", list the version numbers of the files you have locally
- use the VSS2005 Internet service and write a GUI application that provides VSS Explorer functionality
- find out in which database and project were stored the source controlled files you have on the local disk
The vssver.scc file format is proprietary and is not publicly documented.
Unfortunaly, while I know the file format, I don't think I'm allowed to tell you directly.
However, let's see what information can be found about the vssver2.scc files by trial and error.
The metod used below is to create enough sample files and compare them, then modify just one parameter and see the impact in the files written by SourceSafe.
Poking around
Let's start by creating a new database and setting a working folder for the root an empty folder.
set SSDIR=C:\temp\VSS
mkss.exe %SSDIR%
set WF=C:\temp\WF
mkdir %WF%
ss.exe work $/ %WF%
In the working folder, create an file File1.txt.
cd %WF%
echo. > File1.txt
Add the file to the database root folder.
ss add File1.txt -I-
Save the vssver2.scc file just created in the working folder in as File1.scc.
attrib -h -s vssver2.scc
copy vssver2.scc c:\temp\Saves\File1.scc
Repeat the last steps, adding File2.txt and File3.txt into the root folder, each time saving the Vssver2.scc file, into a new file, File2.scc, File3.scc
(instead of creating new files, I simply copied File1.txt into File2.txt and File3.txt)
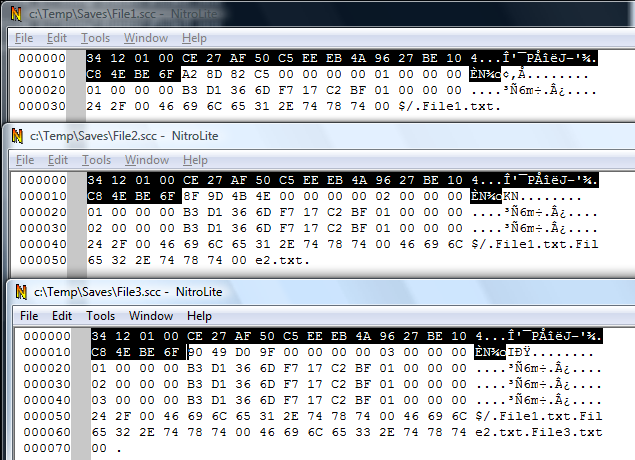
Now let's look with a binary editor at the 3 scc files we saved.
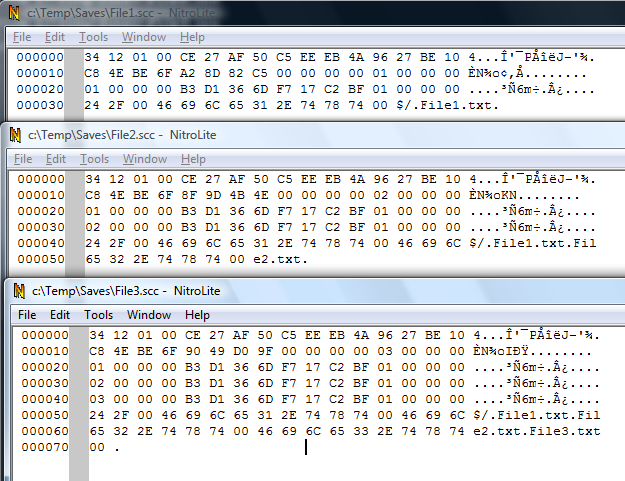
The first thing you'll notice are the NULL-terminated strings in the end of the file.
The Vssver2.scc file seems to contain a block of binary data, followed by the name of the project associated with this file ($/), followed by the names of the files tracked (File1.txt, File2.txt, File3.txt).
The next thing you'll notice is that everytime a new file was added, the size of the block of data before the project and filenames increased with 16 bytes.
That tells you that SourceSafe stores a 16-byte structure for every tracked file.
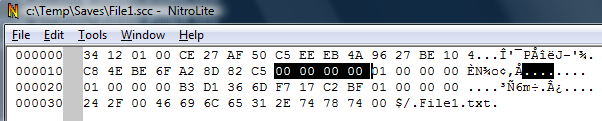
Looking back at File1.scc it means the file records start at offset 0x0020 in vssver.scc, and each such record is 16 bytes.

The first 0x0020 bytes in the file must be related to other information (database or project identification, etc)
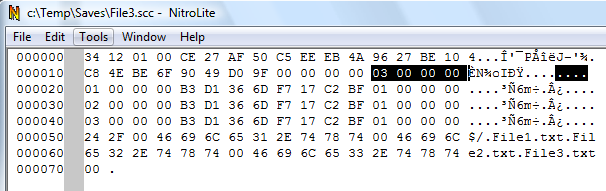
You'll also notice the 4-byte values at offset 0x001C in the file. This number increased each time a new file was added.
Clearly, this value keeps the number of file tracked (the number of 16-bytes records that follow)
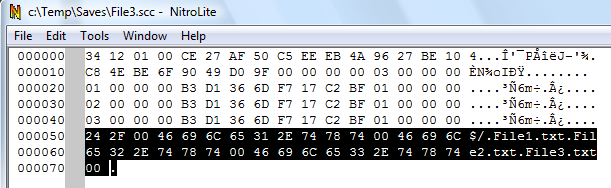
The 4 bytes just before that, at offset 0x0018 are the same in all 3 files, set to 00.
The 12 bytes in the beginning of the file are the same in all 3 files.
Let's try to create some more vssver2.scc files for analysis....
Create a new folder in the database, create a new file named File1.txt, and add it to that project
ss md $/Project -I-
mkdir %WF%\Project
copy %WF%\File1.txt %WF%\Project\File1.txt
ss cp $/Project
cd %WF%\Project
ss add File1.txt -I-
Save the vssver2.scc file just created in the local Project as Project_File1.scc.
attrib -h -s vssver2.scc
copy vssver2.scc c:\temp\Saves\Project_File1.scc
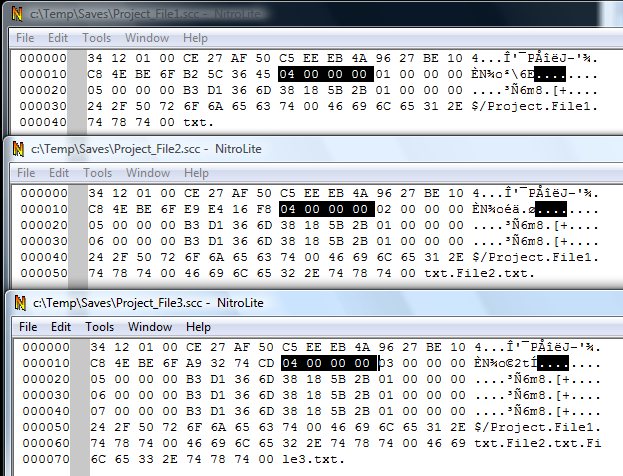
Now let's look at the new set of files.
Everything we've noticed before stands true, except one thing: the 4 bytes at offset 0x0018 are now all equal to 04 00 00 00.
Ok, it's time for a deeper analysis.
From this MSDN page
and from Ted Roche's website you'll find out that
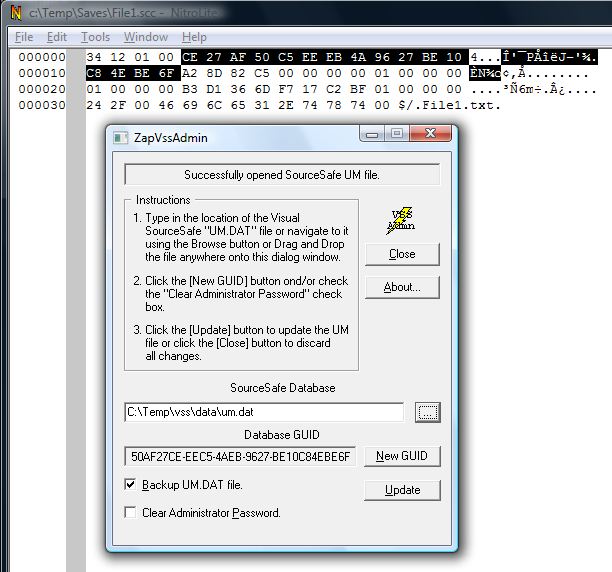
SourceSafe databases are identified by a GUID that is stored in the data\um.dat file. The GUIDSCAN.EXE tool is no longer
available for download in MSDN. However, a while ago I've found out another tool, ZapVssAdmin that aside from
resetting the SourceSafe admin password, it can be used to display (and change if necessary) the GUID of a
SourceSafe database.
So, let's find out the guid of my database. I run ZapVssAdmin and I found out the database GUID:
{50AF27CE-EEC5-4AEB-9627-BE10C84EBE6F}
All of a sudden, the 12 bytes at offset 0x0004 in the vssver2.scc files make more sense, don't they?
Also, using SSNPL tool, let's find out the the file and folders identifiers (physical file names and numbers).
By running the tool multiple times (e.g. "ssnpl.exe $/Project c:\temp\vss\data"), I found out all the identifiers. They are all incremental numbers, in the order I created the files and folders in the database.
$/ - 0
$/File1.txt - 1
$/File2.txt - 2
$/File3.txt - 3
$/Project - 4
$/Project/File1.txt - 5
$/Project/File2.txt - 6
$/Project/File3.txt - 7
The 4 bytes at offset 0x18 start to make sense now.
You'll remember that x86 machines use little-endian byte order, so the DWORD value at 0x0018 offset seems to match the identifier of the project associated with the vssver.scc file.
Thus, for the first 3 files created this DWORD value is 0, matching the $/ folder's identifier, while for the second set of 3 files the DWORD value is 4, matching the $/Project's identifier.
The first bytes in all vssver2.scc files were 34 12 01 00. This translates to a 0x00011234 DWORD value, possibly used as a file signature.
From the first 0x0020 bytes in the file, the only ones that remained unknown are the 4 bytes at offset 0x0014.
These bytes have different values in all the files we've created until now.
Let's look now at the files records.
It's fairly easy to match the first 4 bytes in these record with the file identifiers.
E.g. for the File1.txt, File2.txt, File3.txt in $/Project folder, the identifiers are DWORD values equal to 5, 6, 7
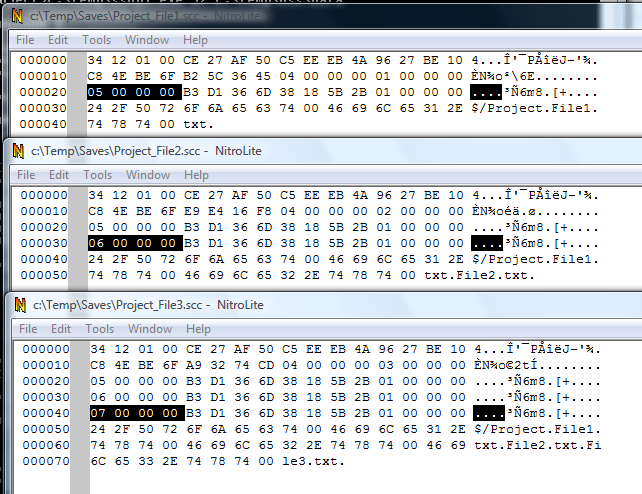
The rest of the bytes in the files records are the same, which kind of make sense since we copied the same file
over and over again, just changing the name each time.
In SourceSafeExplorer, Tools/Options/General set CheckInUnchangedFiles==Checkin. This means that when we'll checkin a file, a new version of that file will be created in the SourceSafe database, even if the file's content didn't changed.
Now checkout and checkin one of the files, e.g. File1.txt, and without modifying anything in this file let's check it back in.
ss checkout File1.txt
ss checkin File1.txt -I-
Then save the updated vssver2.scc
attrib -h -s vssver2.scc
copy vssver2.scc c:\temp\Saves\Project_File3_1.scc
If you compare now the saved file with its previous version, you'll see that last 4 bytes have changed in the File1.txt's record.
They had originally a DWORD value 1, now they are DWORD value 2. Since the only thing that changed is the file's version (we used to have version 1, after checkin we have now version 2),
it's obvious that at offset 0x0C in the file's record VSS stores the file's version that you have locally.
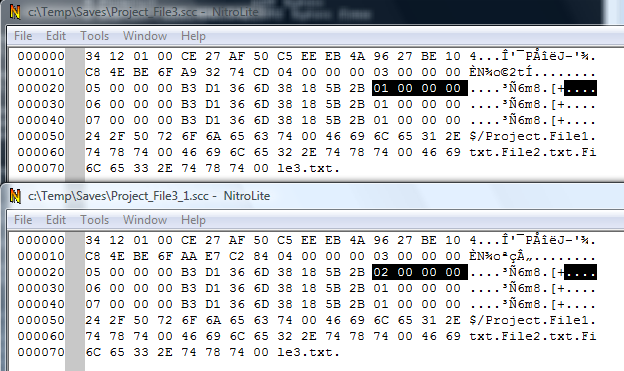
Also, the bytes at offset 0x0014 in the file have changed, so they must be some sort of a checksum for the vssver2.scc file; this also explains why these bytes were different every time.
Let's try now something different with the second file.
Let's check it out, change its timestamp, let the file's content unchanged and check it back in.
ss checkout File2.txt
touch File2.txt (or echo. > %WF%\Project\File2.txt)
ss checkin File2.txt -I-
Then save the updated vssver2.scc
attrib -h -s vssver2.scc
copy vssver2.scc c:\temp\Saves\Project_File3_2.scc
Now compare the file Project_File3_2.scc with its previous version, Project_File3_1.scc.
You'll see that beside the version number changing from 1 to 2, the 4 bytes at offset 0x08 in File2.txt's record are also changed.
It's obvious that the DWORD value at offset 0x08 in the file's record is related to the file's time.
If you look however at Windows functions returning the time of a file, none of them are returning 32-bit values, so this DWORD must be a timestamp.
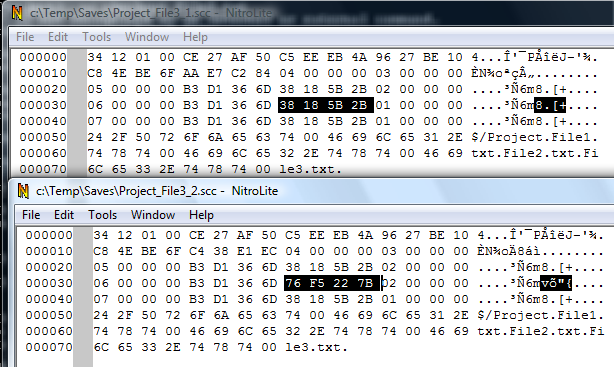
Let's do similar operation with the File3.txt, but this time let's change the file's content, too.
ss checkout File3.txt
echo Modified > %WF%\Project\File3.txt
ss checkin File3.txt -I-
Then save the updated vssver2.scc
attrib -h -s vssver2.scc
copy vssver2.scc c:\temp\Saves\Project_File3_3.scc
Now let's compare the file Project_File3_3.scc with its previous version, Project_File3_2.scc.
This time, beside the already expected changes (timestamp and version number), the bytes at offset 0x04 in the file's record are also changed.
This means the bytes at offset 0x04 in the file's record are a checksum of the file's content.
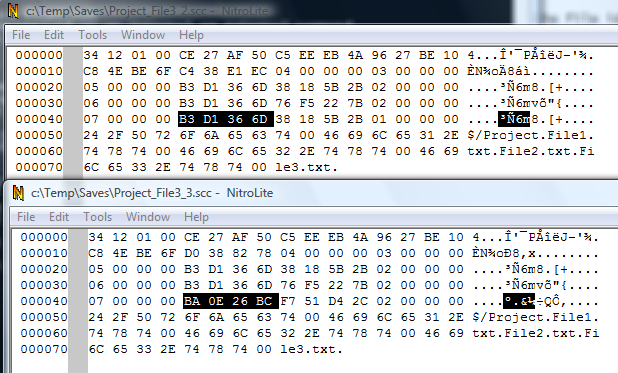
I don't know about you, but when someone talks about 4 bytes(32 bits) checksums, the first thing that pops in my mind is CRC-32 algorithm (the other one being an even less reliable XOR algorithm).
Unfortunately, if you download a tool like Cipher or CRC32c from Borland's site and calculate the File3's CRC32, it will be D7A1BF56 and won't match the value stored by SourceSafe in the vssver.scc file, so VSS must be using something else to calculate the checksums...
The structure of the Vssver2.scc files
It's time to put together what we've learned so far.
A vssver.scc file is composed of 3 sections:
- a FileHeader section of 32 bytes size
struct FileHeader
{
DWORD dwSignature; /* 0x00011234 */
BYTE[16] arrDatabaseGuid; /* a GUID identifying the VSS database associated with the vssver2.scc file */
DWORD dwChecksum; /* a checksum of the vssver2.scc file */
DWORD dwProjectID; /* the number identifying the project from VSS database accociated with the vssver2.scc files */
DWORD dwFileEntries; /* the number of file entries stored in the vssver2.scc file and following this structure */
}
- a number of FileEntry sections, each of them 16 bytes, one entry per each file tracked by the vssver2.scc file
struct FileEntry
{
DWORD dwFileID; /* the number identifying the file in the VSS database that is tracked by this vssver.scc file */
DWORD dwFileChecksum; /* the file's checksum */
DWORD dwFileTimestamp; /* a file timestamp */
DWORD dwFileVersion; /* the version of the file from the VSS database that you have locally */
}
- a FileNames section in the end of the file that contains
- The null-terminated project name associated with this vssver2.scc file
- A list of null-terminated file names that have entries in the FileEntry section
Remaining issues
Q: How does SSNPL calculate the file and folder identifiers?
A: See a description of file numbers in this blog post.
Q: How does SourceSafe calculate the 4-bytes file timestamp?
Q: How does VSS calculate the files' checksums?
Q: How can the checksum of a file be stored in the file itself?
If you investigate deeper and find the answer to these questions, send me a mail and I'll post the info here...
How does a vssver.scc file differ from a vssver2.scc?
Vssver.scc files are created by SourceSafe 6.0 in each folder that contains source controlled-files, after you got those files locally.
SourceSafe 2005 upgrades those files to VssVer2.scc format. One can use VSS 6.0 and create a VssVer.scc file in a folder, then use VSS2005 to upgrade the file, and compare the results.
It's easy to observe that vssver.scc files don't contain the FileNames section with the real names of the tracked project and files (vssver.scc files contain only the binary info from FileHeader and FileEntries).
Also, the FileHeader.dwFileEntries in the vssver.scc files is equal to 0, so the count of the files records doesn't seem to be stored in vssver.scc files.
(Back to SourceSafe and source control integration page)